DOM-Scraping in GTM: Daten Extrahieren leicht gemacht

Management Summary
Daten aus der Website auslesen, ohne auf einen Data Layer oder die IT angewiesen zu sein? Diese Möglichkeit bietet das DOM-Scraping. Wie auch du sämtliche Inhalte dynamisch auslesen und für deine Analysen verwenden kannst, erfährst du hier!
Was bedeutet DOM?
Die Abkürzung DOM steht für Document Object Model und beschreibt den strukturierten Aufbau einer Website. Bildhaft lässt sich der DOM als Baumstruktur vorstellen. Die einzelnen Elemente innerhalb dieses Baumes werden als Knoten bezeichnet. Hierbei kann es sich beispielsweise um Überschriften, Texte, Bilder oder auch interaktive Elemente wie Links oder Buttons handeln.
Das Ziel von DOM-Scraping ist es, den Inhalt dieser Knoten dynamisch auszulesen.
Wofür wird DOM-Scraping verwendet?
Das DOM-Scraping bietet für die Webanalyse vielfältige Vorteile:
- Einfaches Erfassen aller im DOM verfügbaren Inhalte
- Schnelle Implementierung spart Zeit & Geld
- Kein Eingreifen in den Website-Code nötig
Grundsätzlich gilt aber: Wenn ein Data Layer vorhanden ist, sollte immer darauf zugegriffen werden. Das DOM-Scraping dient eher als Alternative oder Ergänzung.
Praktische Anwendungsbeispiele
Hier ein paar Beispiele für die sinnvolle Nutzung des DOM-Scrapings:
Use Case 1: E-Commerce Daten
Im E-Commerce Tracking spielen Produktdaten eine essentielle Rolle in der Webanalyse.
Mithilfe des DOM-Scrapings können sämtliche Daten der Produkte extrahiert werden, sofern diese im Website-Code verfügbar sind: Produktname, Preis, Kategorien und vieles mehr. Der Vorteil ist, dass immer der aktuelle Inhalt der Seite ausgelesen wird. Wenn es beispielsweise mehrere Varianten eines Produkts gibt, wird immer der Inhalt erfasst, der gerade für den Nutzer sichtbar ist.
Zu beachten ist allerdings, dass die auf den einzelnen Seiten verfügbaren Produktdaten schwanken können und somit nicht immer zuverlässig verfügbar sind. Auch hier ist es empfohlen, einen E-Commerce Data Layer zu implementieren.
Use Case 2: Navigation
Du willst wissen, auf welche Links in deiner Navigation am häufigsten geklickt wird? Auch das kannst du mittels DOM-Scraping herausfinden, indem du den Text des Menüpunkts erfasst. Dies ist besonders praktisch, wenn sich die Inhalte der Navigation häufig verändern, zum Beispiel durch Kampagnen.
Use Case 3: Formular
Auch Inhalte eines abgesendeten Formulars können extrahiert werden. Wenn du also in deinem Analysetool sehen willst, welcher Grund für Reklamen im Support-Formular am häufigsten ausgewählt wird, oder welche Themen bei der Newsletter-Anmeldung die Beliebtesten sind, ist das der Way-to-go. Achtung: Immer den Datenschutz beachten, und keine personenbezogenen Daten erfassen!
Schritt für Schritt: Daten extrahieren im GTM
First things first: Das A und O liegt in der Planung. Es ist es wie immer wichtig zu beachten, nur Daten zu erfassen, die du später auch tatsächlich auswerten willst. Mehr ist nicht immer mehr!
Als nächstes identifizierst du die Elemente auf der Website, die den gewünschten Inhalt liefern.
Dazu kannst du die Entwickler-Tools verwenden. Öffne diese in deinem Browser und bewege dich mit der Maus über die Seite hin zu deinem Element. Nun kannst du das Element genauer untersuchen:
(Fast) jeder Knoten ist mit einem Selector ausgestattet. In den meisten Fällen handelt es sich um die ID oder eine Klasse. Diese wird nun in der Zwischenablage gespeichert, um sie später im GTM zu verwenden.

Hier wäre die ID des Elements “referenzen”.
Danach geht es weiter im Google Tag Manager. Es gibt zwei gängige Wege:
Weg 1: DOM Variable
Die DOM Variable verwendest du, wenn du eine eindeutige ID oder Klasse zu deinem Element gefunden hast.
- Erstelle eine neue Variable und wähle den Typ “DOM Element”.
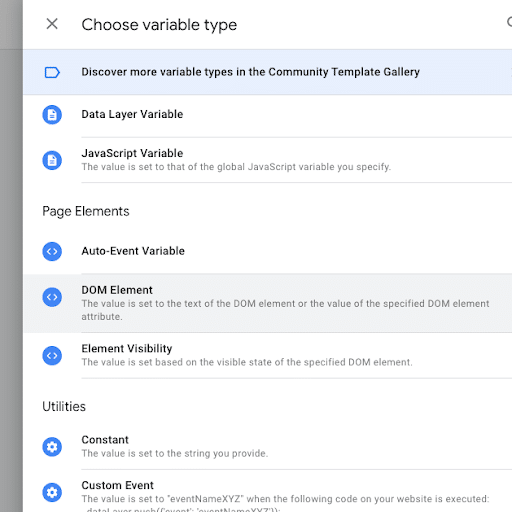
- In der Variablen-Konfiguration wählst du zwischen ID oder CSS-Selector und fügst anschließend den zuvor aus dem DOM kopierten Wert in das Eingabefeld.
- Optional: Wenn du anstatt des Textes den Wert eines Data-Attribute auslesen willst, fülle das Feld “Attribute Name” aus.
- Testing: Öffne den Preview Mode und überprüfe den Wert deiner Variable.
- Schließlich fügst du die Variable zum gewünschten Tag hinzu, um sie an das Analysetool zu übermitteln.
Weg 2: Custom JavaScript
Diesen Weg wählst du beispielsweise, wenn es keinen direkten Selector für das gewünschte Element gibt.
Für diese Methode sind Grundkenntnisse in JavaScript erforderlich.
Sagen wir, unser Referenzen Headline hat ein Child-Element ohne eindeutige Klasse:
- Erstelle eine neue Variable und wähle den Typ “Custom JavaScript”

- Grundaufbau der Funktion: Eine JavaScript-Funktion muss eine bestimmte Syntax aufweisen und immer einen return-value enthalten.
- Element mit querySelector auswählen: Mithilfe der JavaScript Selector Funktionen kannst du dein Element auswählen.
- Text auslesen: Mit der .innerText Funktion kannst du den Text eines Elements extrahieren. Willst du stattdessen auf den Wert eines Data-Attibutes zugreifen, verwendest du das dataSet Object.
- Der fertige Code könnte folgendermaßen aussehen:

- Debugging: Verwende die Console, um deinen Code zu debuggen. Tipps dazu findest du hier.
- Testing: Öffne den Preview Mode und überprüfe den Wert deiner Variable.
- Schließlich fügst du die Variable zum gewünschten Tag hinzu, um sie an das Analysetool zu übermitteln.
Gratulation, du hast Website-Inhalte dynamisch mittels DOM-Scraping erfasst!
Achtung vor Fallstricken!
Das DOM-Scraping ist eine tolle Möglichkeit, Werte dynamisch auszulesen. Trotzdem ist Vorsicht geboten:
Veränderungen im DOM: Die Website-Struktur kann sich durch Anpassungen des Codes schnell verändern. Möglicherweise wird der Selektor des Elements umbenannt, oder der gewünschte Inhalt in einen anderen Knoten verschoben.
Für diese Fälle ist es nützlich, Fallback-Werte zu hinterlegen und die Werte regelmäßig in Reports zu überprüfen, um schnell handeln zu können.
Better Practice: Data Layer
Der Data Layer wurde extra dafür erstellt, Werte für das Tracking zu enthalten – der DOM nicht. Wenn also ein Data Layer vorhanden ist, sollte diese immer in erster Linie verwendet werden!
Fazit
Das DOM-Scraping bereichert deine Webanalyse mit Daten und ist ein schneller & unkomplizierter Weg, um relevante Inhalte erfassen zu können. Achte darauf, es aber als Ergänzung zum Data Layer zu betrachten. Greife wann immer möglich auf den Data Layer zurück, da dieser nicht nur verlässlicher ist, sondern auch unabhängig von Änderungen der DOM-Struktur bleibt.
Mit ein bisschen Routine & unter Einhaltung der Best Practices, um Fallstricke zu vermeiden, kannst auch du deine Analyse mit Daten aus dem DOM anreichern. Viel Spaß beim Ausprobieren!