Recommendation Systems With Google Analytics Raw Data

Management Summary
Use BigQuery data with machine learning
Suggesting visitors the articles that are relevant to them in order to offer a better user experience is a core goal for publishers. On the one hand, this makes users happier because they receive article recommendations that actually interest them. On the other hand, the publisher is happy about a higher engagement rate and dwell time and therefore also about higher advertising sales.
With these thoughts in mind, we have developed an article recommendation engine that uses machine learning to provide visitors with the articles that are relevant to them as recommendations. It works on the assumption that visitors reading similar articles have the same preferences. Based on user behavior, articles that similar visitors have viewed are recommended.
Build or Buy – that already exists
Article recommendations already exist from many providers, but from the publisher’s perspective these are a black box. You pass on valuable user data and do not have full control. This means that insourcing with full data sovereignty is a significant advantage from both a strategic and compliance perspective (GDPR). The individual design and optimization options are also an important asset.
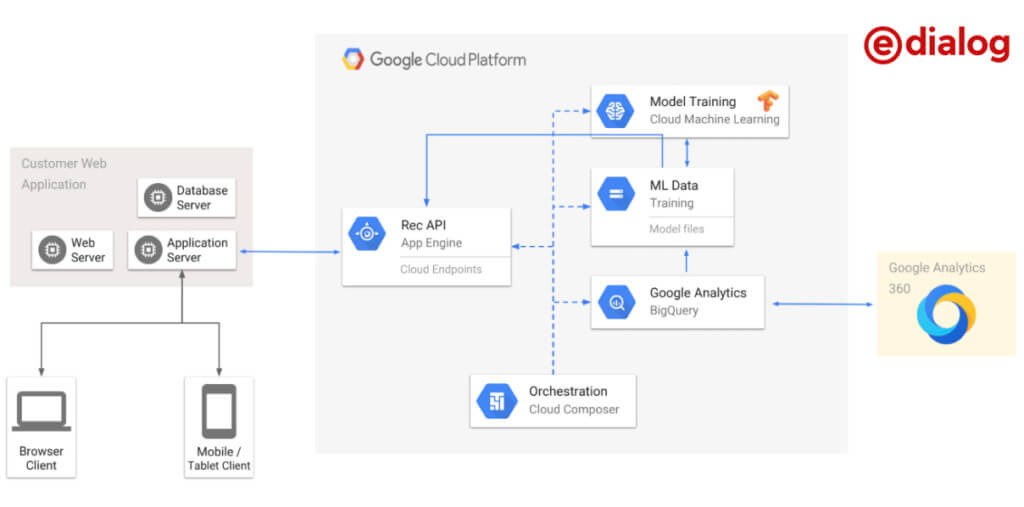
The implementation
The project was implemented in collaboration with Google and Kurier, one of the largest Austrian publishers. The basis for the article recommendations is the valuable raw data from Google Analytics 360. Furthermore, the user data is exported to Google’s data warehouse via the native BigQuery integration. Various cloud services are available there that can be used to implement machine learning projects.
The following figure illustrates which services we use for our solution.
TensorFlow for machine learning algorithms
We created the model with TensorFlow, Google’s framework for machine learning algorithms. Our approach relies on a method called “collaborative filtering”. On the one hand, we assume that visitors with similar user behavior share common interests. On the other hand, we assume that this will be reflected in the behavior of users and that they will access similar articles.
What we are already doing today is optimizing the average session duration. In the future, we plan to include additional key figures, such as the Article Teaser Click Through Ratio and the advertising revenue.
The current approach, the “collaborative-filtering” approach, requires that user data already exists. In order to be able to provide new visitors with recommendations right from the start, we would also like to pursue a “content-based” approach. The fallback solution is to recommend similar articles if user data is not available.



